***
←
→
Data sources, representation
|
Topics
In this lecture, we will look at these items:
- where does data 'come from'?
- how are various types of data represented?
In terms of the data analysis pipeline, the above items belong in the early/beginning part.
The 'knowledge discovery' process, again
Here is another diagram [from 'Principles of Data Mining' by Max Bramer] that shows the data science pipeline:
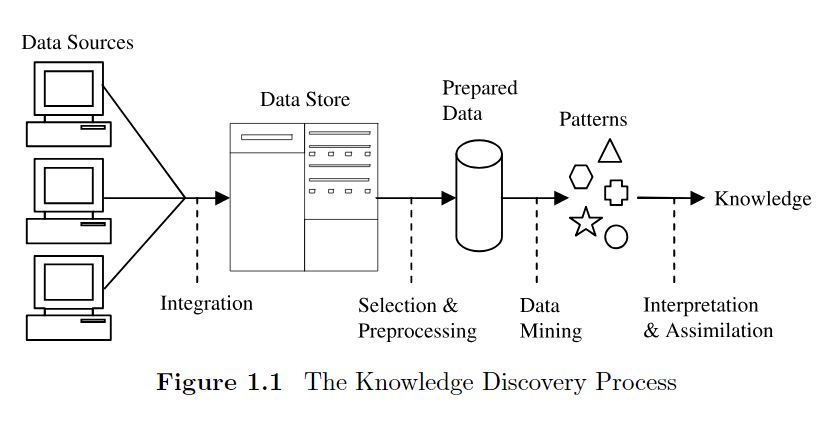
Throughout the course, we will study the various stages of the pipeline. Today, we focus on the very beginning part - 'data sources'.
Where does data come from?
What is the 'what/whom/how' of data?
It turns out that there are multiple sources - which collectively lead to the 'Big Data' explosion we have today.
Let us take a look at the sources.
Two (three) broad sources of data
Here are the two (three) data generators:
- people
- devices/sensors
- (people+devices)
The non-human world does not deal with "data", which is of interest to humans only!
Source: people: web browsing
A quite common, modern-day activity, is web browsing - this creates massive amount of data, in the form of server logs (who visited a page, when, from where), searches, and "clickstreams" [a more detailed version of the first two].
Source: people: purchasing habits
Our commerce-related activities (shopping [both 'live' and online], dining, travel, consumer-to-consumer buying/selling, use of cards...) generate massive amounts of data.
Source: people: social media
As is obvious, we spend so much time on various forms of social media (Instagram, Twitter, Facebook, YouTube, Snapchat, blogging sites, and more) - in addition to just browsing, we comment, 'like', 'upvote', share... - all this activity generates massive data!
Source: people: entertainment
Netflix, Spotify, Pandora, Hulu... We generate data (and profits) while we consume entertainment. Again, we create even more data by 'liking', etc.
Source: people: education
When we take an online class, read a wikiHow page ("on anything"), browse Wikipedia, watch Khan Academy or YouTube instructional videos, or visit 'homework helper' sites, we are generating data.
Source: people: surveys
Surveys, which involve counting/measuring, are an age-old activity [census, land management...]. Today, we can also do them online, which creates more data than ever before.
Source: people: polls
Polls, that measure ratings, are also not new - eg. elections, exit polls... Again, we can do them online now - Qualtrics, Surveymonkey, eateries (eg. Subway), movie theaters, everyone...
Source: people: reviews
Reviews are not new either ([Roger]Ebert and [Gene]Siskel, Consumer Reports, for ex). But today, we have Yelp, Rotten Tomatoes, Fandango, Amazon reviews... again, an explosion of data!
Source: people: cataloging
We generate data, every time we classify things, count and record things...
Source: people: more
In addition, there are data repositories that contain our employment history (eg. Linkedin), court records (marriage, crime...), credit scores.
And, there is now, genomic data as well - for under $100, you can have your genes sequenced., which is enabled behind the scenes by a host of biotech companies.
Source: devices/instruments
Scientific instruments such as particle accelerators and giant telescopes generate massive amounts of data!
On a smaller scale, every scientific experiment involves data collection and analysis.
Source: devices: 'IoT'
EVEN MORE data is being, and will be, generated, when **sensors** [that measure temperature, pressure, light level, sound level, elevation, vibration, wear and tear...] are attached to everyday objects and industrial equipment, and internetworked - this is the Internet of Things, ie. IoT.
A way to think about IoT: what if (almost) every lightbulb, tire, building, plane engine, bridge, fridge etc. had an IP address and a sensor, and transmits data periodically through a network?
Here is an IoT infographic:

Source: people+devices: medical
Fitbit, Nike+, glucose sensors, heart monitors, brain monitors... there is no dearth of 'body-originated' data we can generate, store and analyze!
Source: people+devices: location
Our smartphones are location-aware, thanks to GPS - this alone can create a connect-the-dots view of our daily activities. In addition, traffic sensors on roads and freeways, 'telematics', airport cams (that do face recognition), even cameras on buildings (that track license plates), all create data.
Source: collective
In addition to individuals, the following entities generate and utilize data as well: businesses, non-profits, hospitals, schools, religious organizations, citizen-run clubs and gatherings, governments [economic, environment, agricultural, education, energy, crime/safety, resources, infrastructure, climate/weather, war-related, transportation...].
Sources: summary
So now you have a clear, comprehensive view of 'where' ALL data comes from!
Data representation: overview
Once we have data (from the sources we just studied), we need to be able to 'represent' them digitally - need to follow a convention to record (store) them, so that we can query/analyze them.
By 'representation', we don't mean the details of how data is actually stored on disk - that would be a 'file format', which we will learn about in the next class. Rather, we look at data representation at the 'conceptual' or 'logical' (but not 'physical') level. In other words, what 'whiteboard' conventions can we follow, to describe, or 'model' data?
Data representation: hierarchical modeling
The earliest databases (eg. IBM's IMS from 1966!) assumed a 'hierarchical' view of data. In a hierarchical model, data is stored using a 'tree' structure, with children data (thinner branches) pointing to parent data (thicker branches). Here is the Wikipedia page on hierarchical modeling.
In order to query the data stored in a hierarchical database, we'd need to start at the topmost (root) level, and traverse the data level by level.
A hierarchical data model is well-suited for representing classifications, eg.:

Another example:

Data representation: network modeling
A network model is a step up from hierarchical - data does not need to be organized as a tree, cross links and backward links (many-to-many relations, multiple parents) are allowed:
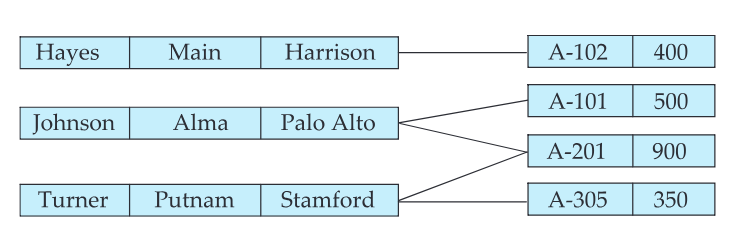
The above shows how a bank could store customers and accounts - each customer can have multiple accounts, and, multiple customers could hold a joint account.
Data representation: relational modeling
Compared to the prior two, the relational model was a breakthrough! In a relational model:
- data is stored as a table - each row corresponds to one 'record' (person, product, place...), and the columns, attributes/properties (eg. age, GPA, location, color...)
- tables can be (virtually) linked to each other, via common columns; new tables can be formed, using 'key' columns from existing tables

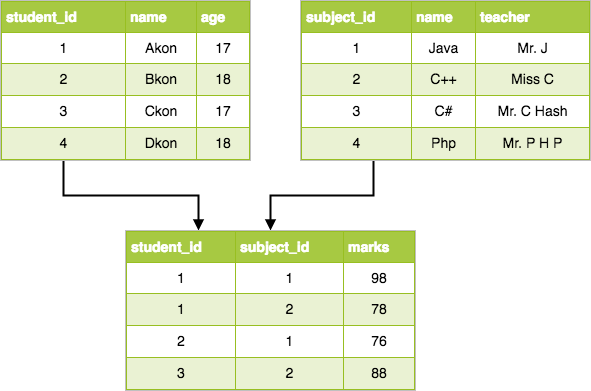
The relational data model 'ruled the world' from 1985 to about 2005, and it is still a dominant data model. But, the advent of the Internet gave rise to more voluminous and less structured data - so, new data models were invented to deal with these.
Data representation: document model
Here, data is a collection (an unordered list, or a 'bag') of "documents", where each document is like a record (a row in a relational table), ie. it contains attributes and values.
Eg. here is a database with just three 'documents' [note that the third document has a slightly different structure compared to the other two, and that the 'name' column is called 'name' in the first doc, and 'fullName' in the other two - such flexibility with the organization of data inside each doc is the KEY to this model's success!]:

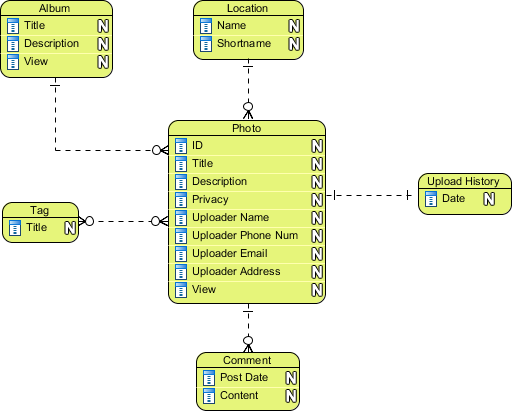
Data representation: graph model
The graph model is the most flexible organization ever possible, to model any (and every!) form of data. Here, data is stored in 'nodes' (containers, that can be specific (eg. a student) or general (the concept of a 'university'), which are simply linked together (via specific link types) to create a (vast, eventually) graph, eg.
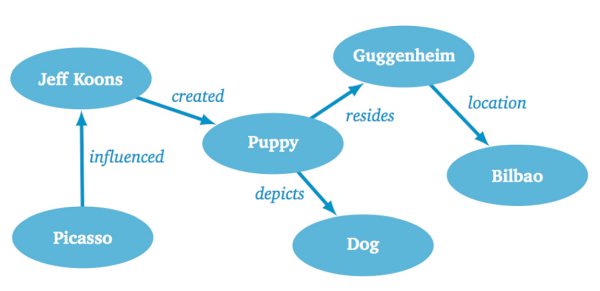
Data from all other models (hierarchical, network, relational, document...) can be converted to a graph model.
Here is more on graph models/databases.
Data representation: vector model

ANY piece of data (a sentence, song, image, floor plan...) can be converted to an array (list) of numbers, ie. a (mathematical) VECTOR! Such a data model (ie data representation) is called a 'vector embedding' or vector model.
Here is more - DO read it - it is how ChatGPT's data is embedded (via a 'Large Language Model' aka LLM)!!
Why create embeddings at all, ie. why model images, text, audio... this way (as numerical arrays, ie. vectors)? Because SIMILAR MEANINGS BECOME CLUSTERED TOGETHER, ie. THEIR VECTOR TIPS WOULD BE FOUND TO LIE CLOSE TO EACH OTHER. This in turn means that we use such clusterings, for search, classification, etc. Cool!