Logical view: 'relation'




'Full' functional dependence is a "good" thing.

A table 'cannot not' have entity integrity!!

Whereas entity integrity has to do with a single table, referential integrity relates to two tables (loosely, 'don't allow invalid pointers').


In RL, NULLs can't be entirely avoided (look here, for 'interpreted as any of the following').

What if a table were a datatype (similar to an int, Vec3D, ComplexNumber, etc)?! Specifically, what operations could be perform on them (eg. similar to addition, square root on doubles)?!



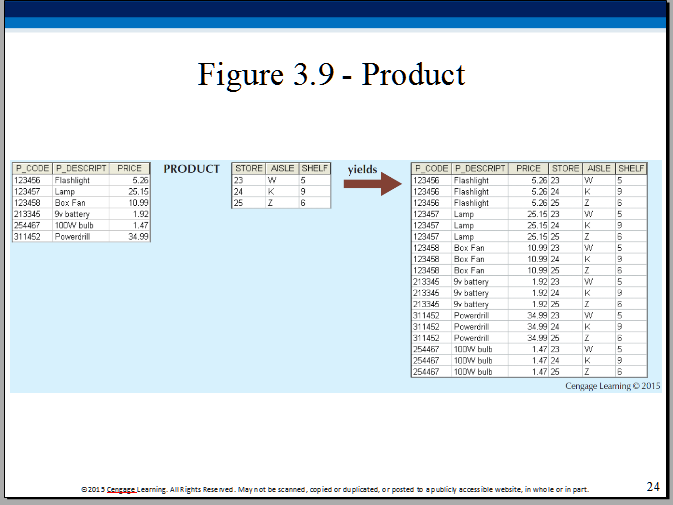



Cartesian product of the two tables (product of rows, juxtaposition of columns):
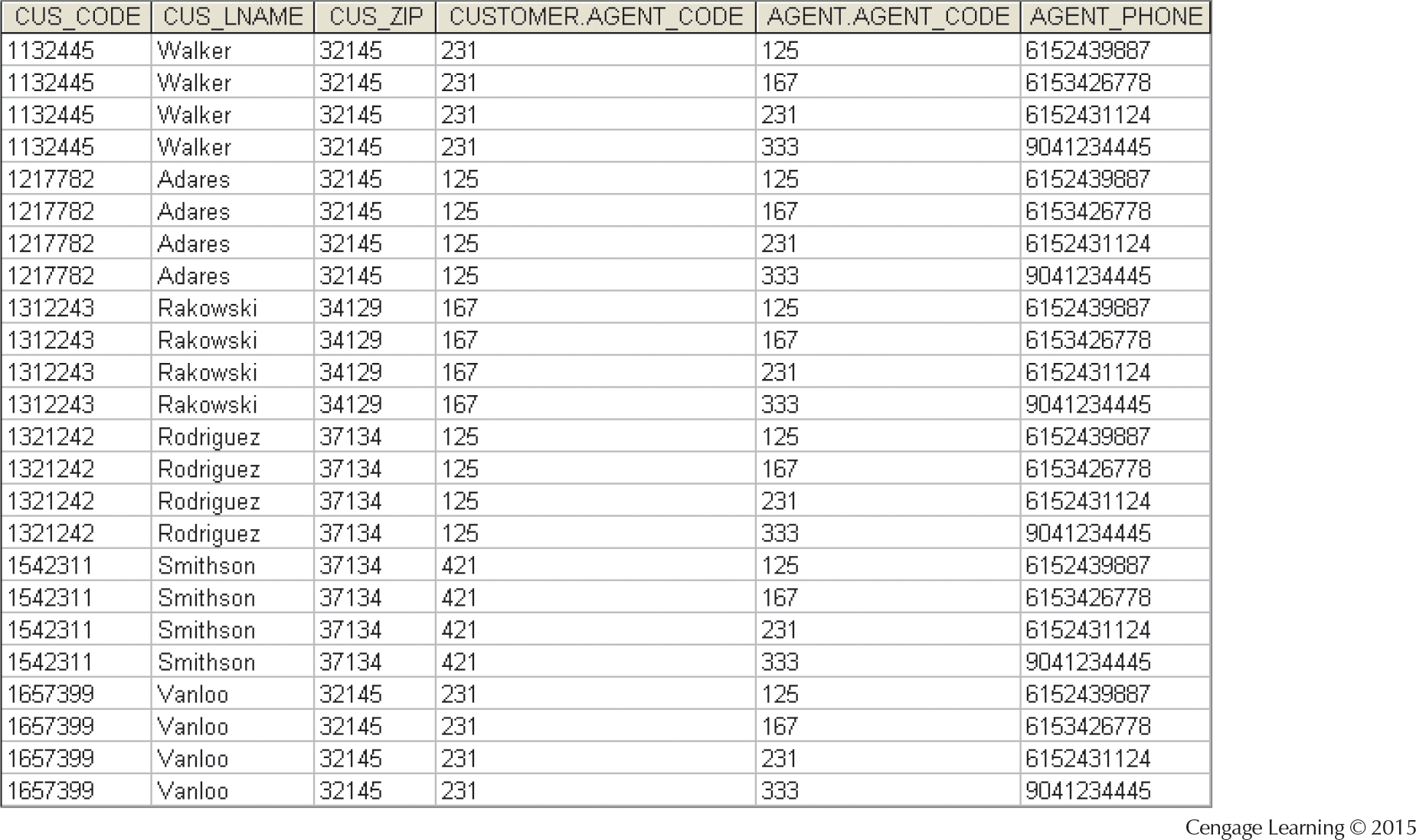
Select only rows with identical values in the common (joining) columns:

Project away, ie. remove one of the two duplicate columns:

Result (the table above): natural join.
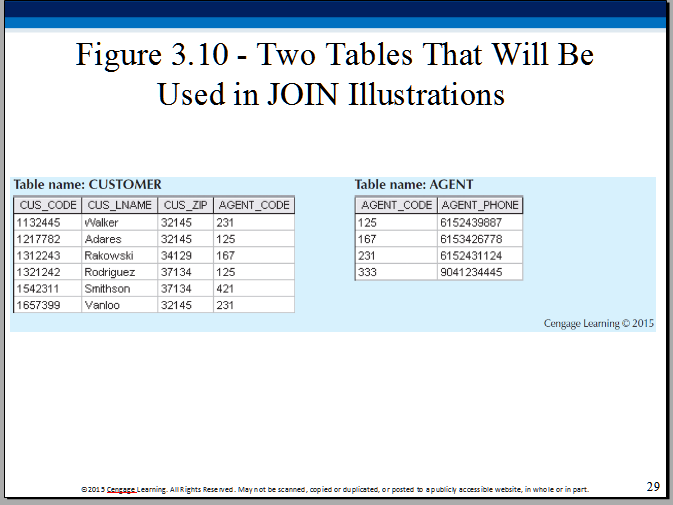
Output all rows of the left (CUSTOMER) table, including ones for which there are no matching values in the join column in the other (AGENT) table:

Note that an outer join is an "inner join plus" [it is NOT an opposite of inner join].
Output all rows of the right (AGENT) table, including ones for which there are no matching values in the join column in the other (CUSTOMER) table:

Outer joins are useful in exposing missing information [in our example, customers who don't seem to have an agent, and, agents who don't seem to have customers].
A 'full outer join' is a union of left outer join and right outer join - output all the rows from both tables, including ones for which there are no matches in the other table - this could result in nulls on the left side of some rows, as well as nulls on the right side of others.
This clip shows the various types of joins [thanks, Yash Gupta, for sending this]:

We're dividing by A and B in the divisor (bottom) table. There's (A,5) and (B,5) in the dividend (top) table, so we output 5 as the result; if the dividend were to contain (A,9) and (B,9) also, then we'd output 5 9 as the result.

A data dictionary is metadata about tables (only); a system catalog, that includes (is a supeset of, although confusingly, the two are conflated in RL) the data dictionary, and more.