***
←
→
Business Intelligence
("BI")
|

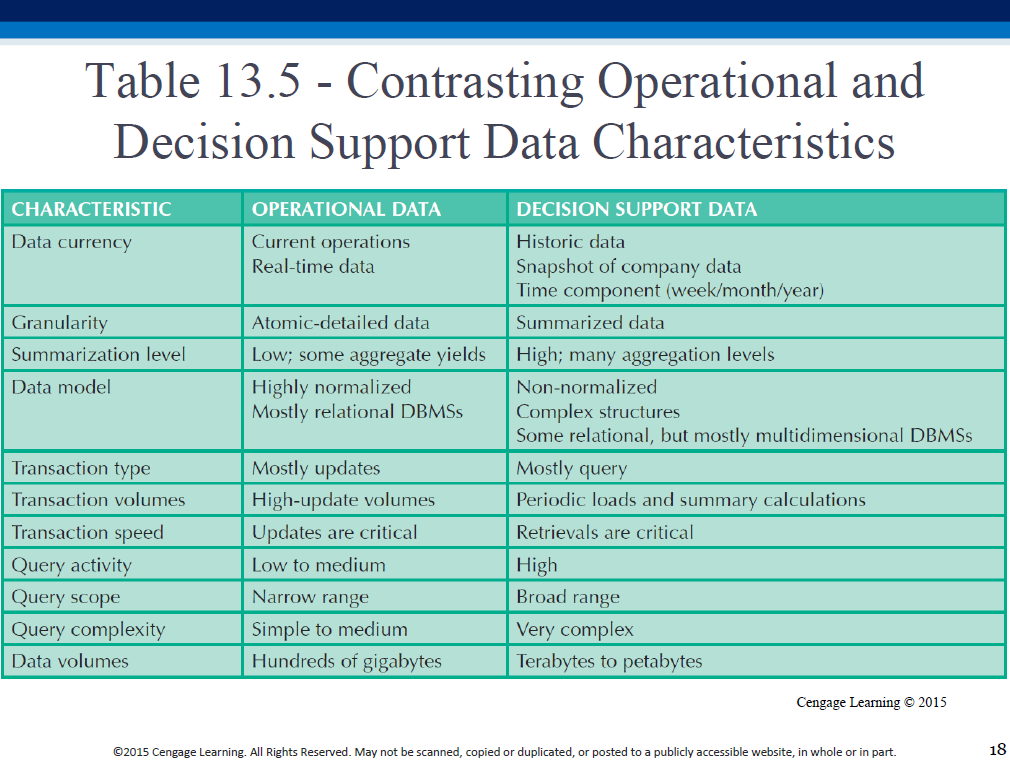
Transactional, operational data: individual units.
'Analytical', decision-support data: aggregated.
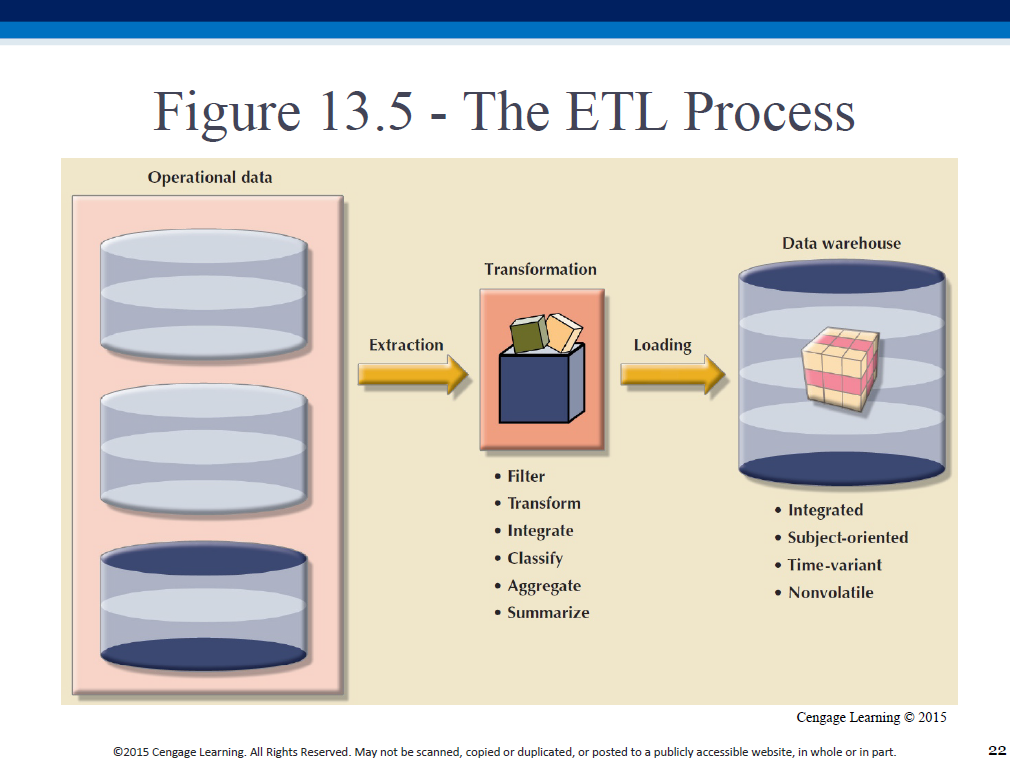
ETL is a classic "schema on write" process, where we define a schema (table structure) first, THEN load the data into that structure.
An ETL-related job ad:

A sample star schema
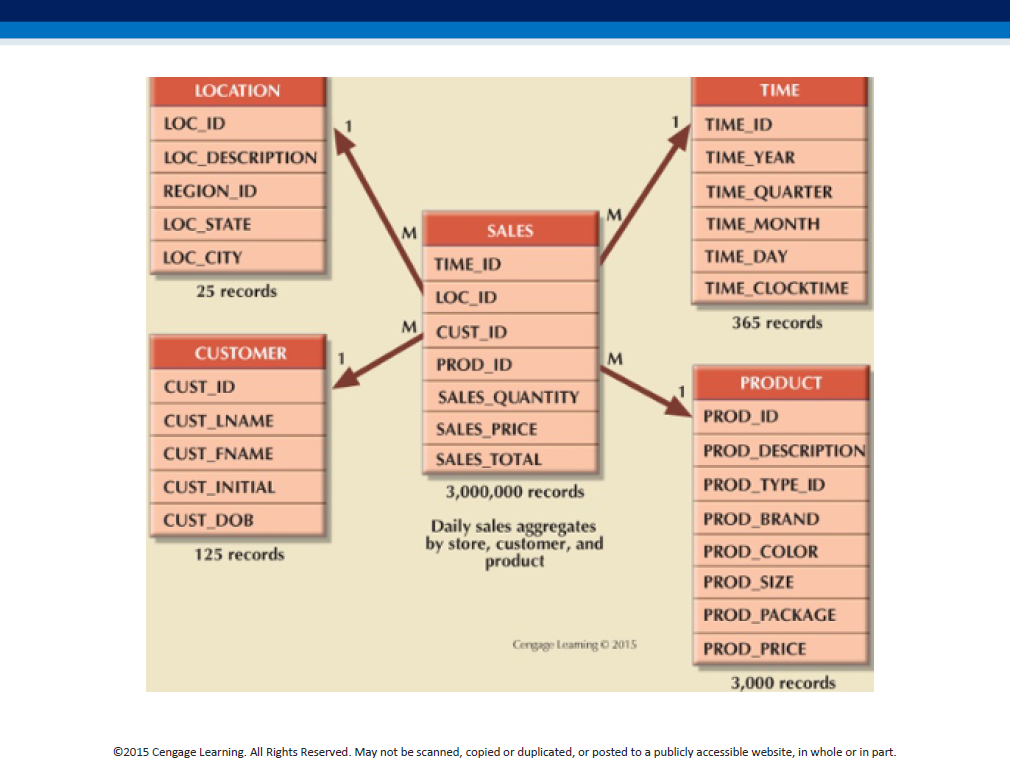
We have the fact table (of transactions) at the center, and denormalized (all-in-one) dimension tables all around.
Here is another representation.
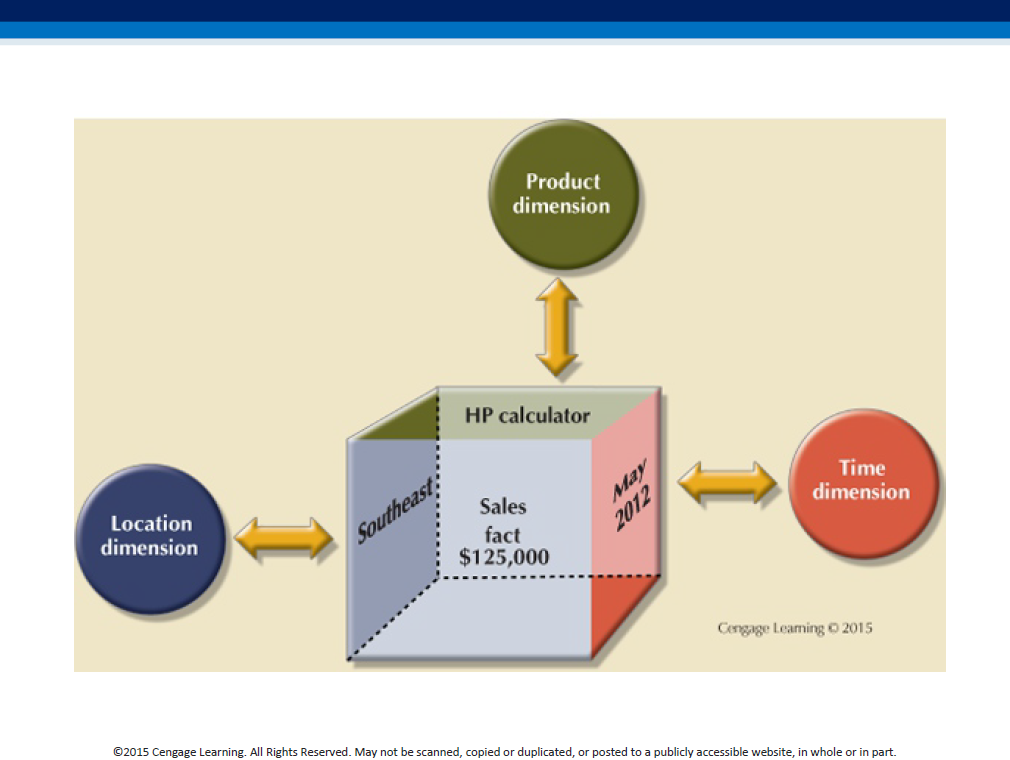
Note: "dimensions are qualifying characteristics that provide additional perspectives to a given fact; dimensions provide descriptive characteristics about the facts through their attributes."
Each fact (transaction) can now pictured to be located in a multi-dimensional cube where the axes are dimensions. Eg. a 3D representation of our data for the above schema would look like this:
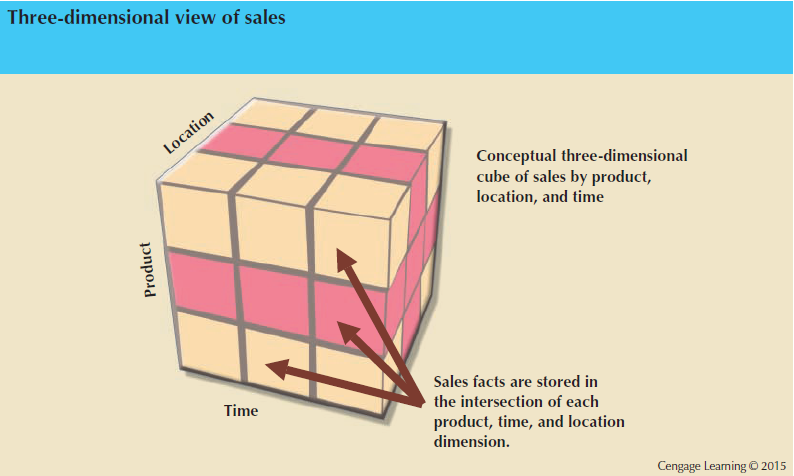
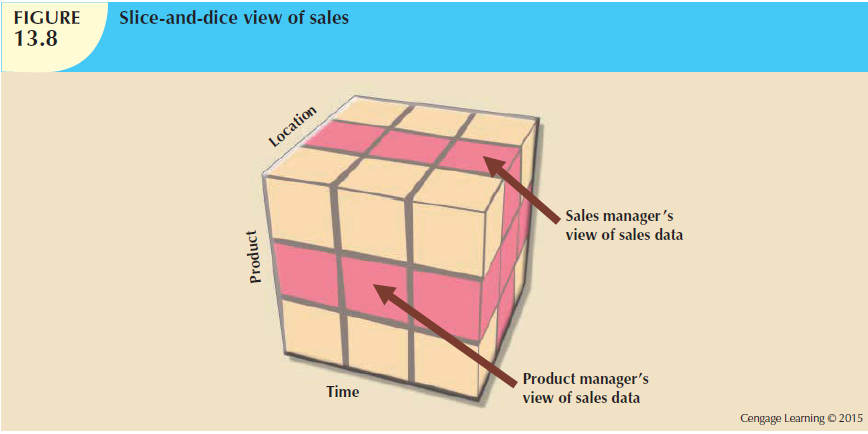
Slicing and dicing the cube provides specific insights..
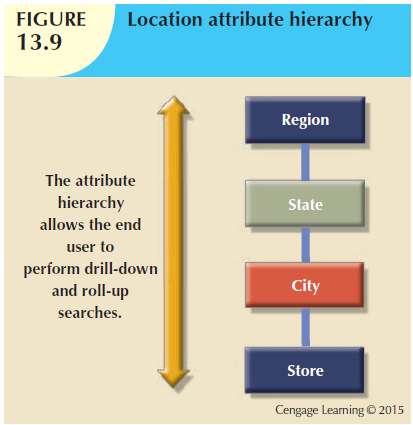
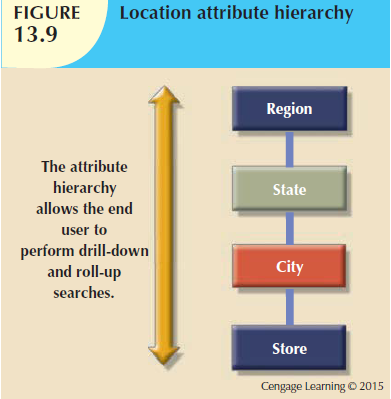
Additionally, an attribute hierarchy would provide drill-down/roll-up capability as well, eg.
Snowflake schema
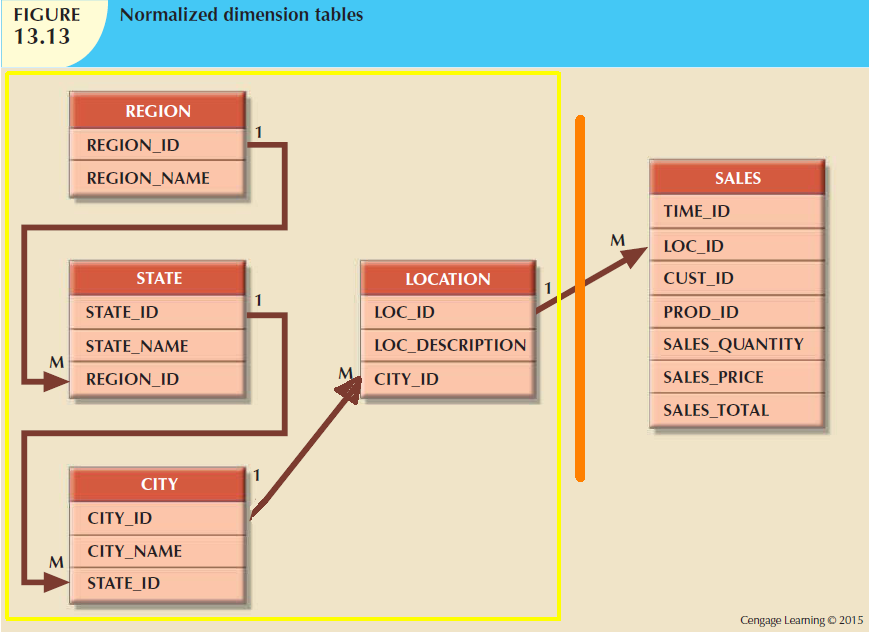
Dimensional tables can be normalized so that they have their own dimensional tables - this is done to simplify the design, but requiring navigation across the normalized chains.
Here is another representation.

There are four different ways in which we can organize (structure) a data warehouse:
- 1. star schema: fact table FKs point to a single level of dimension tables (points of a star)
- 2. snowflake schema: each dimension table can be normalized to create a 1:M chain
- 3. the fact table can be supplanted with all the columns in the star/snowflake dimensions
- 4. a separate fact table can be created for each attribute in a dimension hierarchy
To denormalize a fact table (#3 above), we simply add extra 'dimension' columns to it, and fill them with redundant data - this permits fast queries (no joins needed) at the expense of disk space (and cleanliness of design).
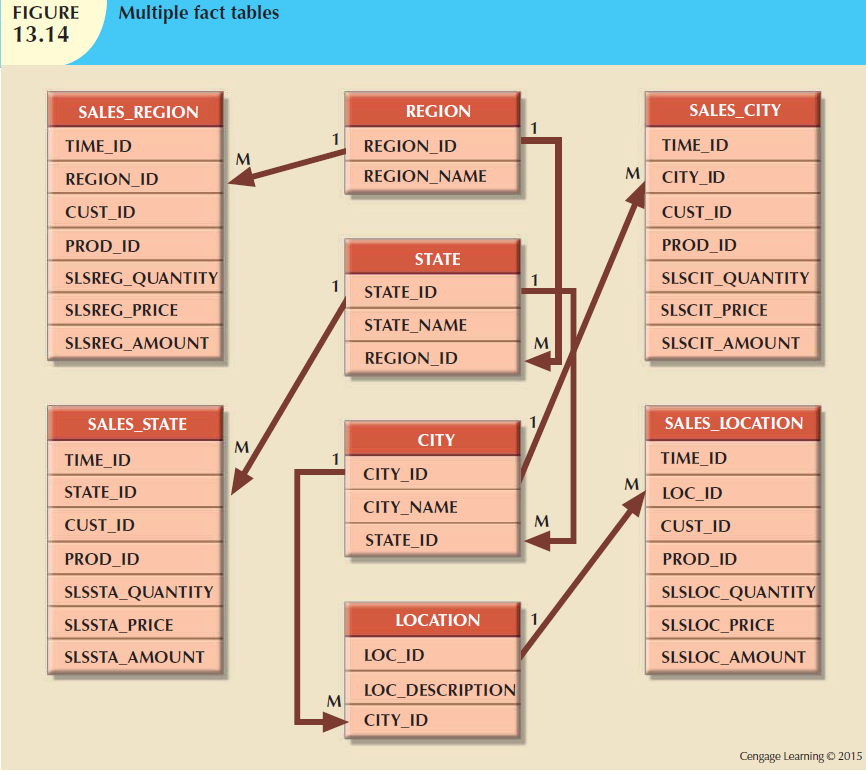
Redundant fact tables!
Instead of a denormalized fact table (#3), or a fact table pointing to denormalized star dimensions (#1), or a fact table with lowest attrs pointing to a chain of rolled-up attrs, ie. snowflake schema (#2), we can create multiple fact tables, one for each level in an attr hierarchy (#4) - it is a different form of denormalization, where the redundant data is stored in physically separate tables.
A summarization...
Fact tables that we see in the middle of star/snowflake schema, are ALWAYS denormalized, with multiple repeating values in the columns that link to dimensions - eg. multiple date values, product values, location values, POS terminal # values etc (because each row in a fact table contains those columns as raw 'facts').
Dimension tables, in a star schema are ALSO denormalized - eg. location dimension, with city,state,region columns, will have repeating values for states (because many cities are in each state), and repeating region values (because many states are in each region).
Dimension tables in a snowflake schema are normalized, because we create a chain (hierarchy) of them using the star's dimension columns.
The fact table ALWAYS stays denormalized. Such a fact table is said to employ star schema, if we use star-like denormalized columns for BI - eg. to find out how much of a product we sold in a city, we'd query the fact rows for city name, and if we need it, can also do state-level analyses (because states are listed in the location dimension table).
Using a snowflake schema, doing location analysis for a product at a city level is similar to the above paragraph - we simply look for the city name, and if necessary, get extra info about the city (eg tax rate) by looking at the dimension table. BUT to do state level analysis, we need to follow the city->state link, and use the state-level dimension table ie traverse a branch of the snowflake.
To avoid traversing those branches in a snowflake, we trade off ('waste') space by creating extra 'copies' of the fact table, where a column such as city (lowest value in the hierarchy of 'location') is REPLACED instead with 'state' values, and in another copy, with 'region' values. This lets us do star-like analyses again, because a fact row directly points the state table, and in another copy, directly points to the region table - no traversing the chain necessary (at the expense of extra storage).
Which schema (star or snowflake) is used to model the warehouse, determines whether we maintain denormalized (or normalized) dimension tables [fact tables always stay denormalized].
'For BI purposes, the idea is to take the 'single unified view' of data which is in the fact table (which contains numerous columns (think of a single Amazon purchase order item) - they can be categorized into dimensions, and in each dimension, even be hierarchically grouped - an example would be 'location'), and DERIVE additional tables, with data pre-aggregated along those (hierarchies of) dimensions. This lets us slice-and-dice (along dimensions), and zoom in/out (along just one dimension), all without expensive querying at runtime (on billions of rows), because the 'group by' calculations have been done already (that resulted in those aggregated data tables).'


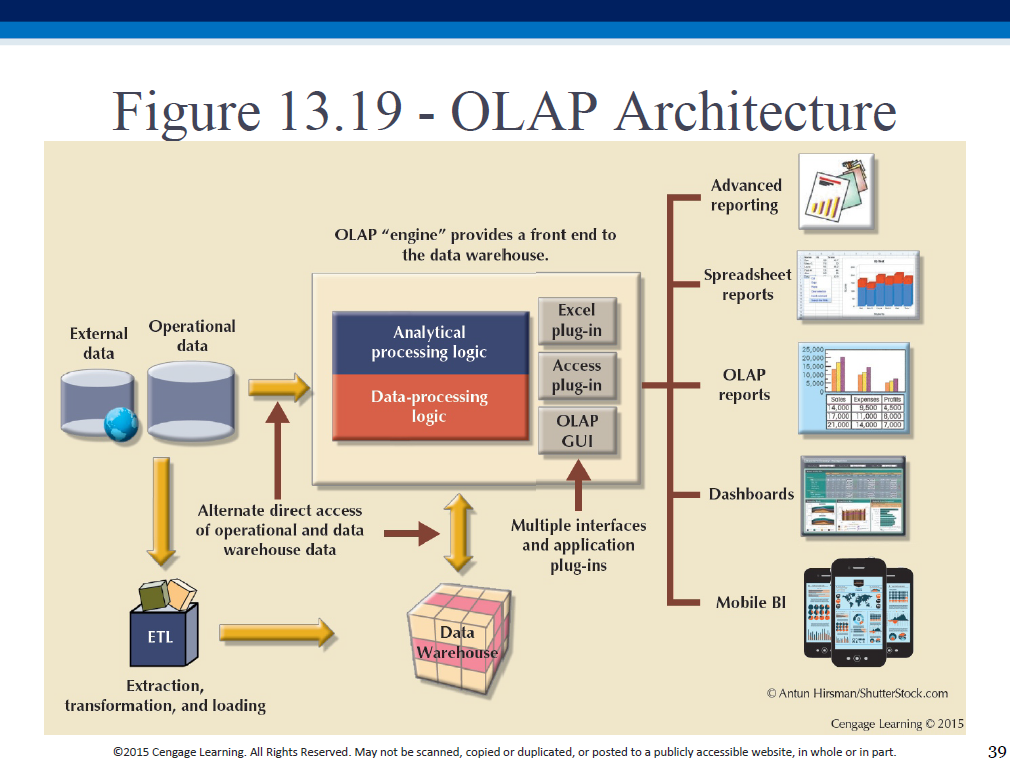
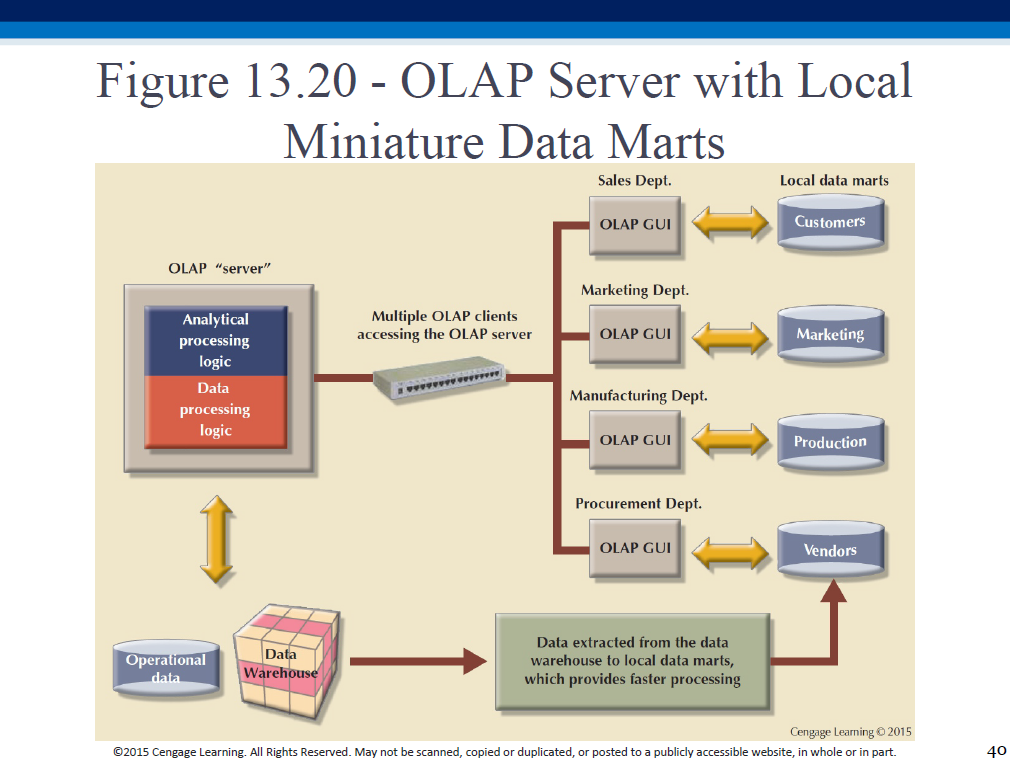
ROLAP, MOLAP
Relational OLAP:

Multidimensional OLAP:

BI-oriented SQL extensions
ROLLUP and CUBE are GROUP BY modifiers - they help generate subtotals for a list of specified columns (see examples that follow). Depending on granularity of the columns (eg. US_REGION vs STORE_NUMBER), these subtotals help provide a rolled-up (aggregated) or drilled-down (detailed) analysis of data.

ROLLUP, CUBE: usage examples
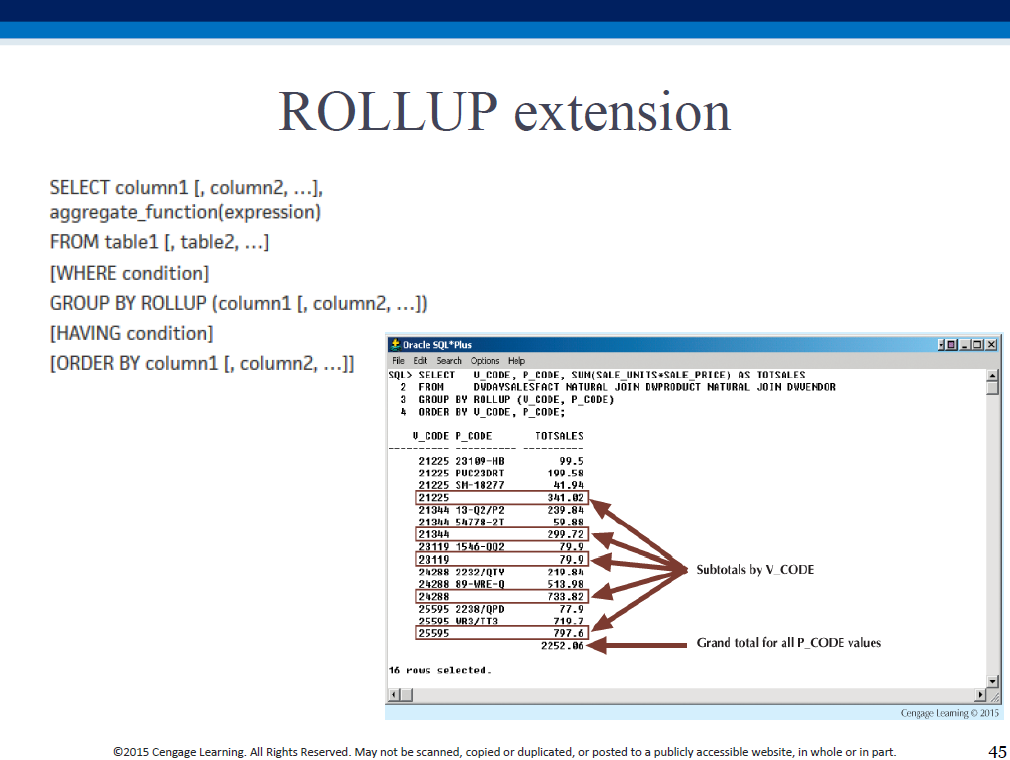
"Subtotal for each vendor - all products; sum of (the only set of) subtotals".
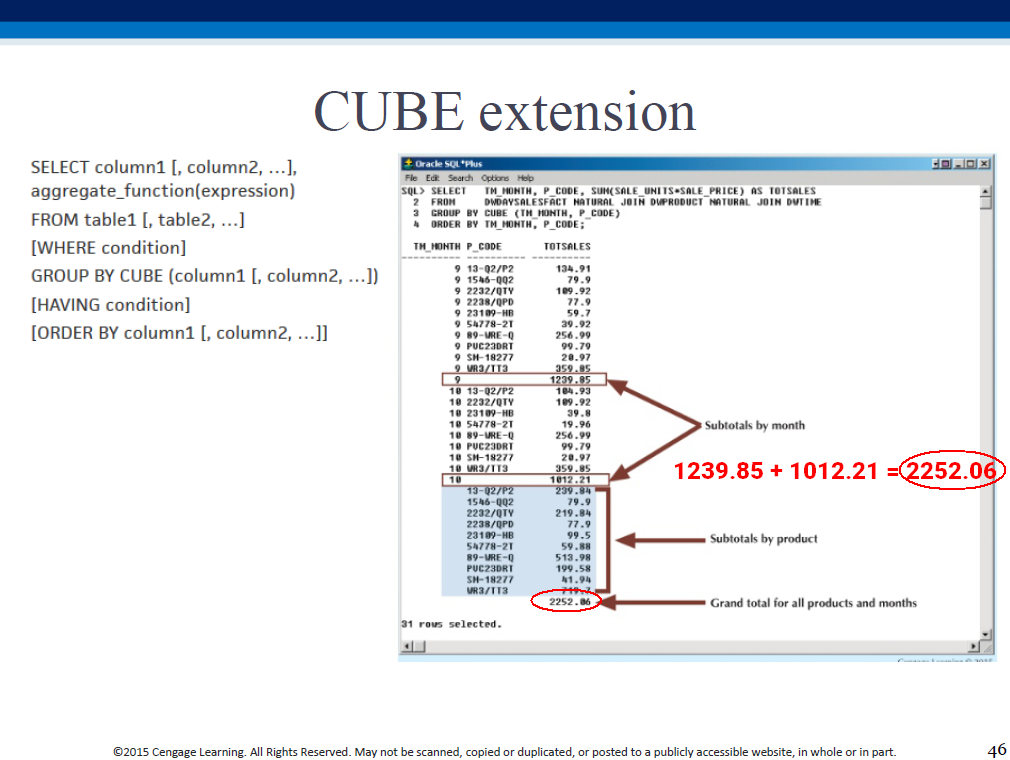
"Subtotal for each month - all products; subtotal for each product - all months; sum of (either set of) subtotals".
Data Lakes, etc.
A 'traditional' data warehouse is an ETL-based, historical record of transactions - very RDB-like (schema-on-write).
A 'modern' alternative is a 'data lake', which
offers a more continuous form of analytics, driven by the rise of unstructed data, streaming, cloud storage,
etc. In a data lake, data is NOT ETLd, rather, it is stored in its 'raw' ("natural")
form [even incomplete, untransformed...] - it is 'schema on read', where we create a
schema AFTER storing (raw) data in a DB. A data warehouse built to make use of a data lake,
is a 'lakehouse'; more here.
Also, look up: ELT, 'reverse ETL'.
The three modern alternatives to ETL (data lake/lakehouse, ELT, reverse ETL) have come into existence,
simply because of the sheer volume/variety/velocity of today's data.













{kind=link}
{kind=link}