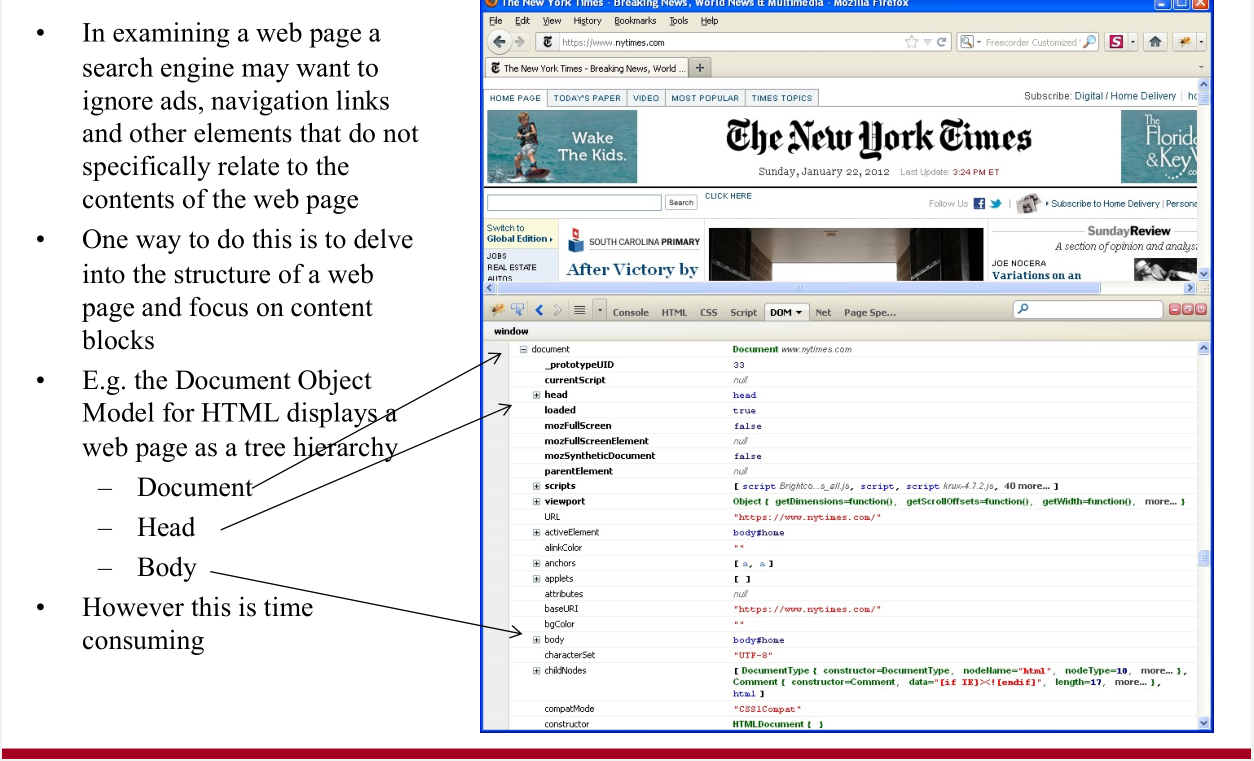
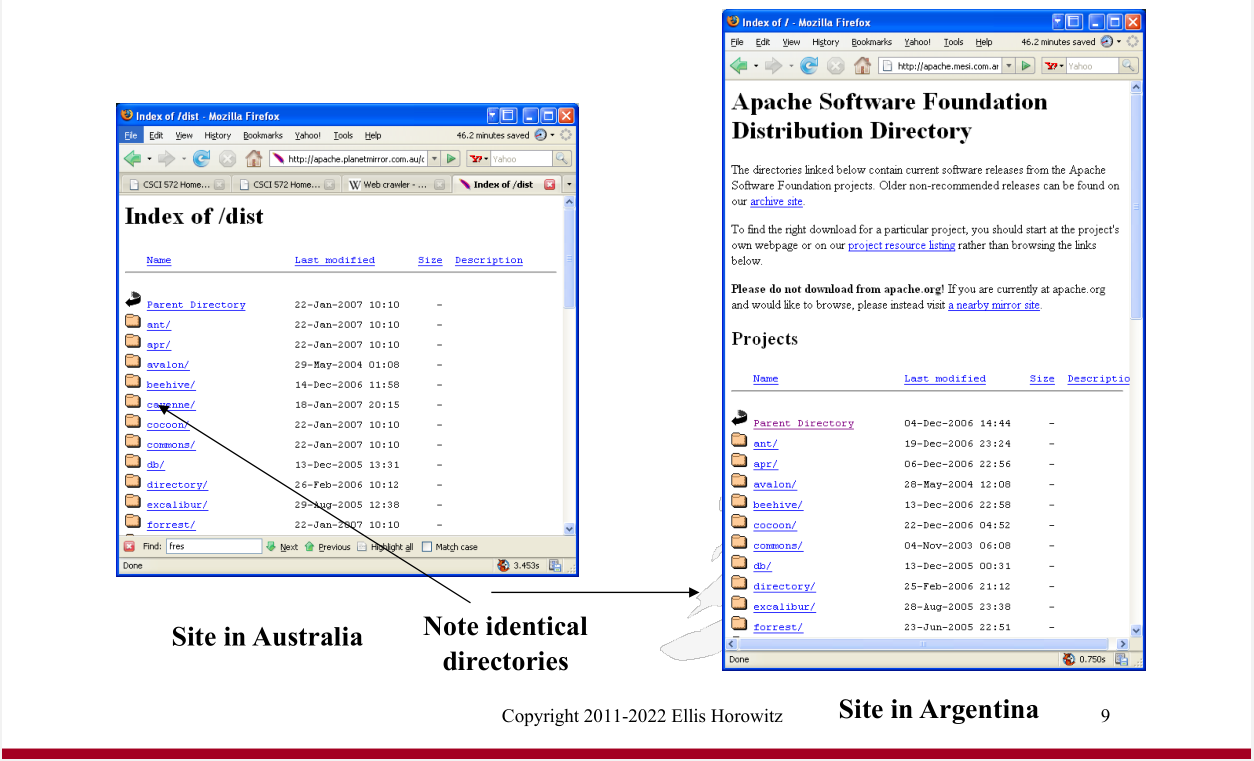
Definition [of deduplication]

Deduplication |









https://bytes.usc.edu/~saty/tools/xem/run.html?x=MD5










FYI if you are interested: in p.475 of our text is a probabilistic approach to this that reduces the # of shingle comparisons we need to make.

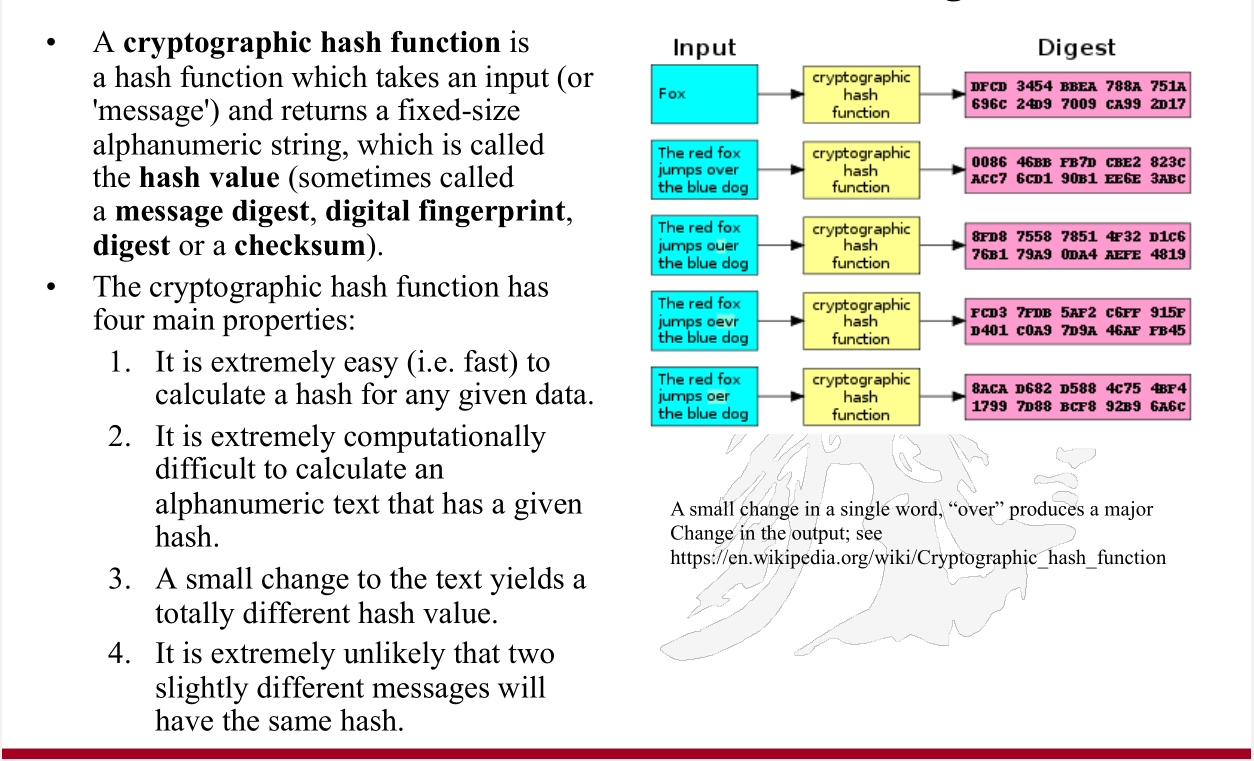
SimHash (aka Charikar Similarity) is essentially a dimension reduction technique - it maps a set of weighted features (contents of a document) to a low dimensional fingerprint, eg. a 64-bit word.
And, documents that are nearly identical have nearly similar fingerprints that differ only in a small # of bits. In other words, similar inputs lead to similar outputs (hash values), hence 'Sim'Hash; other hashing techniques, eg. MD5, do not have this property (in other words, even a tiny change in the input leads to a huge change in the output). This similarity property is what makes SimHash, an excellent tool for similarity detection of documents.
Here is the SimHash paper.


Example:

Q: which bit pattern pairs are almost similar?



So we can 'rotate, sort, check adjacent' 'B' times (eg. 64 times; depending on how many bits we have), to discover (almost) all the near-duplicates.
In other words:
Here is a nice page on SimHash, and this is a Google paper that discusses using SimHash at scale.