Addresses of variables
As we noted earlier, EVERYTHING (program code, and data that the program operates on) resides in memory:
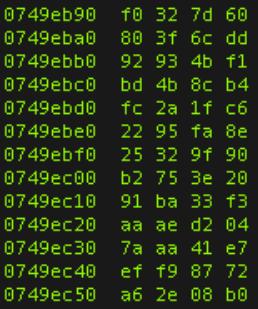
In the above, the left column denotes contiguous memory addresses, and the right column, memory contents.
Addresses
|
C/C++ provides detailed (fine-grained) access to MEMORY - that is what this lecture is all about.
The idea is to be able to access data, using its memory address.
• hex
• addresses of variables
• pointers
• pointers to pointers
• references
• arrays: memory locations
• array access via pointers
• new, delete;malloc, free
• pointers and references as function args
• constructing 2D arrays (arrays of arrays)
Even though bits are expressible in binary form (0=off, 1=on), binary numbers become syntactically large (too many digits) too fast: 0,1,10,11,100,101,110,111,1000....0b1100100 (binary for 100)..
So we use the hexadecimal (16-based, 2^4=16) counting system for more compact expression: 0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,10,11,12..0x64 (hex for 100)..
Specifically, you'll see memory locations (which are bit-based, hence binary-expressible) be refered to using hex notation. Eg. 0x47321A might be a memory location/ID/"address".
As we noted earlier, EVERYTHING (program code, and data that the program operates on) resides in memory:
In the above, the left column denotes contiguous memory addresses, and the right column, memory contents.
So variables (because they're data of int, float, etc types) are stored in memory, at specific memory locations (determined by your program as well as OS).
Eg. when you create 'int k=5;', the variable 'k' is stored in 4 bytes of memory (int is usually 32 bits long, ie. 4 bytes, and each byte is always 8 bits long). How can we find out the memory ADDRESS (location) of k?
int k=5;
cout << k << " " << &k << endl;
&var is how to get the address of a var (exercise: practice getting addresses of more vars).
A pointer is a TYPE of variable - just like a var can be of int, float, char etc, it can be of type 'pointer'. To create a point type var, we use the * notation:
int *p; // p is a variable that is of type "pointer to int"
In the above, p is a "pointer to int", which is what int * means. If we'd said 'int p;' instead, p would simply be an int var.
Q:But what does this MEAN, ie. what can p HOLD?
A: p can/should hold, as its value, A MEMORY ADDRESS! Specifically, p will contain a memory address at which an int is/can be stored. In other words, p can point to the address of an int type var (such as 'k' that we created).
So how to make p point to an int var? Combine the two steps:
int k=5, *p; // k is of type int, p is of type int *
p = &k; // THIS is how we assign k's address (&k) to p :)
cout << p << " " << &k << endl; // identical
This is how to picture a pointer var:
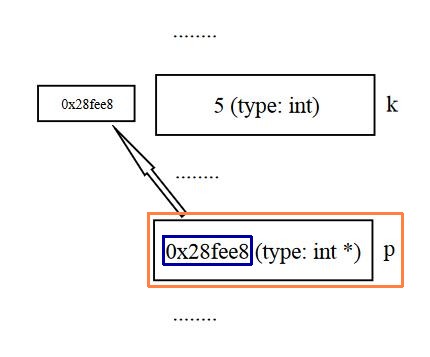
We just had p (type int *) point to k (type int). Note that p ITSELF is a var, which has a memory location too - can we point to IT? Of course :)
int k=5, *p;
p = &k;
int **q; // q is pointer to "a pointer to an int"
q = &p; // in q, we store p's address, ie q points to p
cout << q << endl; // will print p's location
Now we have:
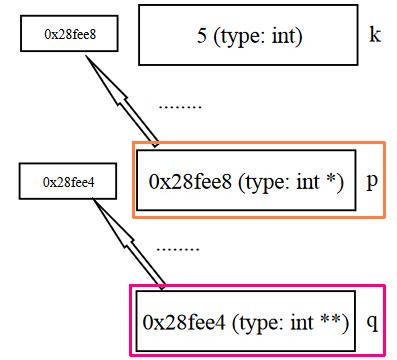
So we have p pointing to k - what is the point of pointing? :) We can ACCESS and MODIFY k's contents, via p - we do so by 'dereferencing', ie following a pointer to access data.
int k=5, *p;
p = &k;
cout << p << " " << (*p) << endl;
(*p)++; // INCREMENT k, indirectly
cout << (*p) << " " << k << endl;
Given a point (var) p, *p denotes the CONTENTS of what p is pointing to.
This is a VERY POWERFUL capability, especially when we start pointing to a BLOCK of memory (eg. that of a stored 16M image) - we can access the contents (using *p etc), MODIFY it too (eg. color correct our 16M image); likewise, if we point to device memory (on a scanner, camera, Kinect, FitBit, Nest, smartcard, etc, etc), we can grab, and possibly modify and set, device data!
Earlier we had q, being a pointer to a pointer. Can we dereference q (twice!) to get to k?? Yes.
int k=5, *p, *pp;
p = &k;
cout << (*p) << endl;
(*p)++; // INCREMENT k, indirectly
cout << (*p) << " " << k << endl;
int **q = &p; // make q point to p, which itself points to k
(*(*q))++; // coolness: increment k, by chasing down TWO pointers!
cout << (**q) << " " << (*p) << " " << k << endl; // all identical
Why stop at int **q? You can even create an int ***r to point to q, and so on. The point (pun) of all this is, memory locations/addresses can themselves be stored in other memory locations, and can be operated on like data (eg * does referencing).
Exercise: dereference pp above - what happens (and why)?
Here is more on pointers, dereferencing: http://cslibrary.stanford.edu/106/
We can print out the memory locations of array elements like so:
int numStudents = 15;
int agesOfStudents[numStudents]; // STATIC allocation of 15 elements
for(int i=0;i<15;i++){
cout << &(agesOfStudents[i]) << " " << agesOfStudents+i << endl;
}
We've encountered the & 'address' operator before, so &(agesOfStudents[i]) should make sense - it simply denotes the address of element agesOfStudents[i].
But what's with agesOfStudents+i??!! That works too, because for an array, the array's NAME itself is a POINTER to the first (0th) element!!
agesOfStudents points to agesOfStudents[0], agesOfStudents+1 points to agesOfStudents[1], agesOfStudents+2 points to agesOfStudents[2], and so on. NOTE THAT +1 will automagically point to the NEXT element after the top element, EVEN THOUGH each element takes up 4 bytes! In other words, +1 is not a 1 byte increment, it is a 1 int (4 bytes) increment :) In general, the + will 'simply' increment to the next song, video clip, game character.. whatever the array happens to store!
Rather than statically pre-allocate an array, we can DYNAMICALLY allocate memory as well (based on runtime conditions, eg. the size of video we recorded and want to video edit), using pointers to blocks of memory.
Dynamic memory allocation is a very flexible, efficient, powerful feature of C/C++ (it is also the source of tons of crashes (due to badly written software) and security holes (again, due to badly written software)).
There are two ways to dynamically allocate (and free up) memory: using malloc() and free() ('C style'), and using new() and delete() ('C++ style'). Let us look at these in turn: C++ way first, then C.
int n=6;
int *a;
a = new int[n]; // dynamically obtain a pointer to 6 ints.
for(int i=0;i<n;i++) {
*(a+i) = i; // store 0,1,2,.. at locations #0,#1,#2..
}
for(int i=0;i<n;i++) {
cout << (a+i) << ": " << a[i] << ", same as " << *(a+i) << endl;
}
// 'delete[]' deletes array mem, 'delete' deletes an atom of mem
delete[] a;
In practice, there is no good reason to write *(a+i) over a[i], other than pedagogical. In other words, since an array variable ALWAYS AUTOMATICALLY is treated as a pointer, no need to say *(a+i) , when a[i] seems more intuitive. Even when there is an expression involved, [] is better than using *(): eg. to access just the even elements of an array, saying a[2*i] is cleaner-looking than *(a+2*i).
For comparison, here's C-style mem allocation:
// be sure to #include < cstdlib>, because
// that is where malloc and free are declared
int *b;
// need to specify count, unitsize; need to cast
b = (int *)malloc(n * sizeof(int));
for(int i=0;i<n;i++) {
*(b+i) = i*i;
}
for(int i=0;i<n;i++) {
cout << (b+i) << ": " << b[i] << ", same as " << *(b+i) << endl;
}
free(b); // frees up what malloc allocated
In the code above, malloc() returns a typeless, 'generic' pointer as its return, and we need to 'cast' it to (int *) - reason is, when we do pointer arithmetic, eg. *(b+i) above, the compiler needs to be able to set up code such that the '+i' is able to skip appropriate number of bytes for each element [in the above, each +i will skip 4 bytes, because we're handling ints].
Again: new(malloc) and delete(free) are VERY powerful, and are UNIQUE to C/C++.
Pointers and addresses have been around since 'C'; C++ adds one more way (type) to access memory, it is called a reference type:
#include <iostream>
#include <string>
using namespace std;
int main() {
int k=5;
int& r = k; // r is of "reference type", MUST always be initialized
cout << r << endl; // we're accessing k, via its reference
r = 10; // we're modifying k, via its reference
cout << r << " " << k << endl;
}
Confusingly (and unnecessarily!), we can even create a pointer to a reference (which itself points to a variable), and use it to modify the variable! Continuing with the example above:
#include <iostream>
#include <string>
using namespace std;
int main() {
int k=5;
int& r = k; // r is of "reference type", MUST always be initialized
cout << r << endl; // we're accessing k, via its reference
r = 10; // we're modifying k, via its reference
cout << r << " " << k << endl;
int *p = &r; // p points to r (which points to k)
*p *= 2; // double r's (ie. k's) value
cout << *p << " " << r << " " << k << endl;
}Why create such a new (reference) type? Because it helps simplify syntax, when we write functions that deal with blocks of memory (eg. an Instagram filter) - passing a var's reference into a function helps keep the code cleaner, compared to passing in a pointer to the same var. To illustrate, below are two versions of a program that shows how to implement the classic 'swap()' function that swaps the values of its input vars - one uses pointers, the other, references - notice how clean the reference version looks, both in the function definition, AND the call.
Pointer-based:
#include <iostream>
using namespace std;
void swap(int *a, int *b) {
int tmp;
tmp=*a; // safe-keep a
*a=*b;
*b=tmp;
}// swap
int main() {
int x=4,y=6;
cout << x << " " << y << endl; // 4 6
swap(&x,&y);
cout << x << " " << y << endl; // 6 4, works!
}// main()
Reference-based:
#include <iostream>
using namespace std;
// note that we use '&' in the arg list, instead of *
void swap(int &a, int &b) {
int tmp;
// note how we access and modify a and b - WITHOUT USING *
tmp=a; // safe-keep a
a=b;
b=tmp;
}// swap
int main() {
int x=4,y=6;
cout << x << " " << y << endl; // 4 6
swap(x,y); // note that we simply pass in x and y, NOT &x and &y
cout << x << " " << y << endl; // 6 4, works!
}// main()
Looking at the above, you can see that using references make the function call simpler, and makes the body of the function simpler; the only place that contains reference syntax, is the function's argument list [where & is used, instead of * that is used in the pointer version].
In C/C+, when we make function calls, we can pass parameters (arguments) into the called functions, in two very different ways: pass-by-value, pass-by-reference.
Pass-by-value: a COPY of the parameter value is made, for local use (inside the function); the original (that the caller supplied) is NOT "hurt" (ie. not modified)!
Pass-by-reference: rather than input a var, we input a pointer to data, or a var's reference - in either case, the function CAN MODIFY data (the pointed-to contents, refered-to var)! This is VERY useful when we deal with HUGE amounts of data (eg. when a function that brightens an image's pixels needs to access and modify all the pixel data).
Study the following program - it shows how to pass to a function, the following: a regular variable, a reference, a pointer, an array name (which is a pointer). Look at the arg list of the called function (aFunc) to see how to specify the syntax. And, look at the body of the function to see how the reference, pointer and array name are used to MODIFY incoming data.
#include <iostream>
#include <string>
using namespace std;
void aFunc(int a, int& b, int *c, int *d) {
a *= a; // this will NOT modify 'w' in main()
b *= b;
*c *= *c;
d[2] *= d[2]; // we can likewise modify other elems if we need to
}// aFunc()
int main() {
int w=4, x=8, y=12, z[5] = {0,1,2,3,4};
aFunc(w,x,&y,z); // expect w to not change; x, y and z will be changed
cout << w << " " << x << " " << y << " " << z[2] << endl;
}A 2D array can be statically declared and manipulated using two array indices:
int TicTacToeBoard[3][3] = {{0,0,0}, {0,0,0}, {0,0,0}};
A dynamically allocated 2D array (eg. to read in image data) can be visualized as a POINTER TO AN ARRAY OF POINTERS (where each pointer in the array points to a row of data).
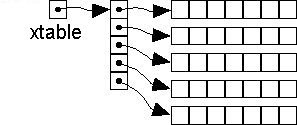
Here is the C++ way (using new+delete) of allocating memory, eg. for a 24x12 table of floats:
float **xtable; // pointer to pointer[s]
cout << xtable << endl; // bogus value
xtable = new float*[12]; // NOTE how we do this!
cout << xtable << endl; // top address of our array of pointers
for(int i=0;i<12;i++) {
xtable[i] = new float[24]; // each row points to 24 elems ("columns")
}
for(int i=0;i<12;i++){
for(int j=0;j<24;j++){
xtable[i][j]=45; // store 45 in everything
}
}
for(int i=0;i<12;i++){
for(int j=0;j<24;j++){
cout << xtable[i][j] << " ";
}
cout << endl;
}
We need to output our 2D array data to a 'PGM' image file on disk, which we can then view.
To create a file on disk, we need to #include fstream, and use an 'ofstream' object to open a file, write grayscale pixel data [0..255] into it, then close it.
Here is starter code that outputs a pgm image file, of 512x256 (pixel) resolution - compile and run this in your IDE - note that it CREATES a new (image) file on disk!
You can view the resulting image file using this viewer [which we referred to, in the previous slide], or using Irfanview, etc.
Fun!!! You now have a simple but ultra-useful toy: you can create dozens (hundreds!) of grayscale PATTERNS by adding extra computations where pixel data gets created (we currently make all the pixels be value=45). THIS IS AN EXCELLENT WAY TO LEARN PROGRAMMING!
Here is the output of the program from the previous page:

Not very exciting? Indeed. It can only get more interesting from here on :)
Here is an online version of a lovely (out of print) book on image processing, written by Gerard Holzmann at AT&T Bell Labs (C, Unix and C++ originated there!).
In the book mentioned above, you'll find pretty images (patterns) in black and white, created by deceptively simple formulae [presented in Chapter 6]. Try to create as many of these as you can, using the .pgm creation template that you just used. Again, doing so an excellent, fun way to learn coding:
repeat:
do some (more) coding
compile and run
look at the result, admire your creation
Note - after learning C++ and Java, you should be able to 'trivially' pick up Python, JavaScript, R, etc. - and in those languages, you can create math art patterns as well.