(De/)Normalization
|
(De/)Normalization
|

Loosely speaking:

[http://rovingcrafters.com/]



Employees of the construction company work on projects. Each employee has an ID, name, job title and corresponding hourly rate.
Each project has a number, name and assigned employees. An employee can be assigned to more than one project.
The company bills clients for projects, based on hours worked by employees.
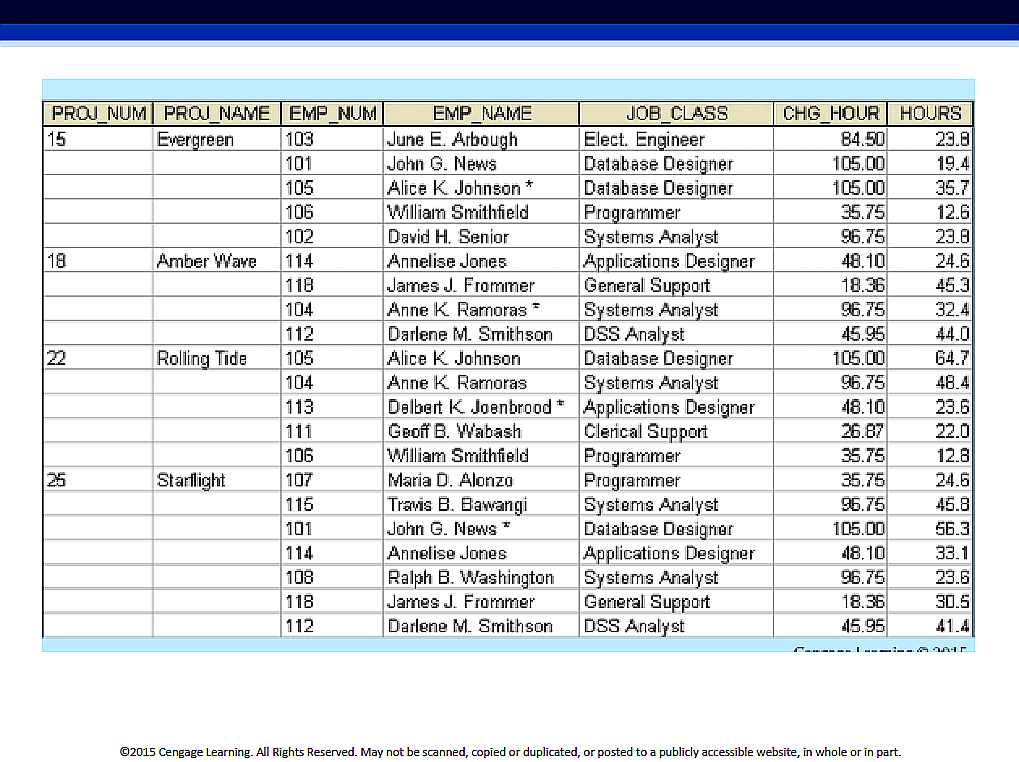
The construction company periodically generates a report like so:
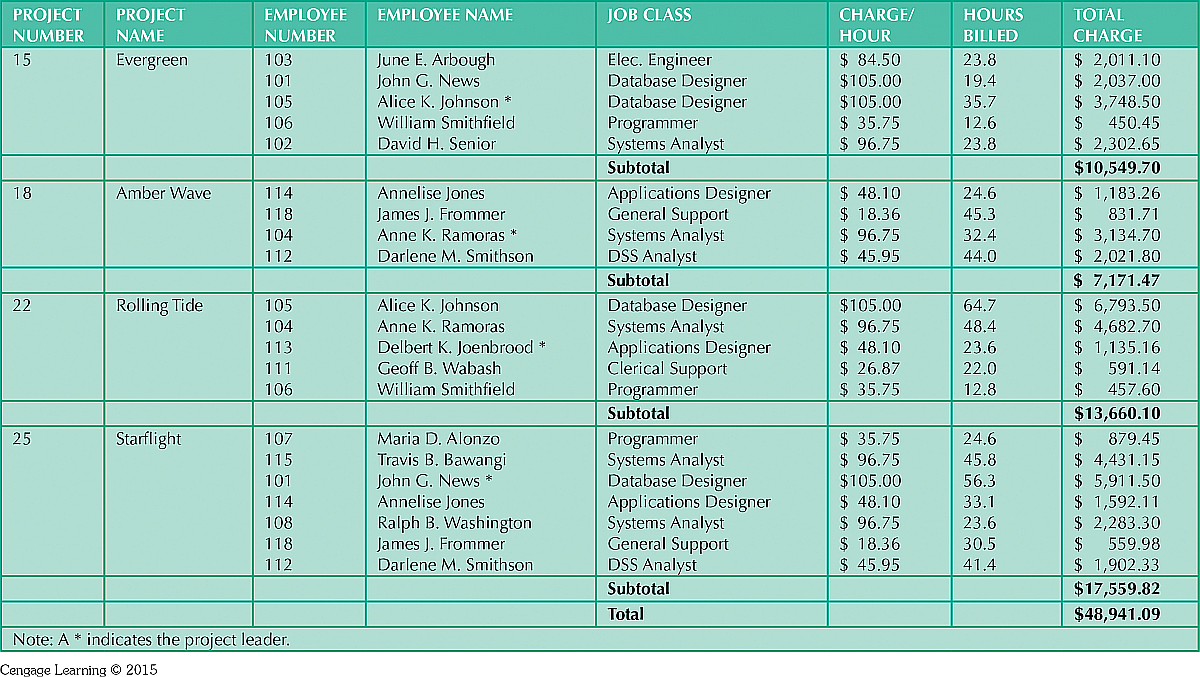
Here is our table again:
There are numerous issues:
We have 'repeating groups' (for each project, we list all details about each employee) - our table is un-normalized, ie. is in '0NF' :)
So, we need to clean up the design!

Normalization is a systematic process that yields progressively higher 'normal forms' (NFs) for each entity (table) in our db. We want at least 3NF for each table; in RL, we stop at 3NF.


Normalization how-to, in one sentence: work on one relation (table) at a time: identify dependencies, then 'normalize' - progressively break it down into smaller relations (tables), based on the dependencies we identify in the original relation so that "only the PK, the whole PK and nothing but the PK" acts as a determinant! But how?? Details follow..
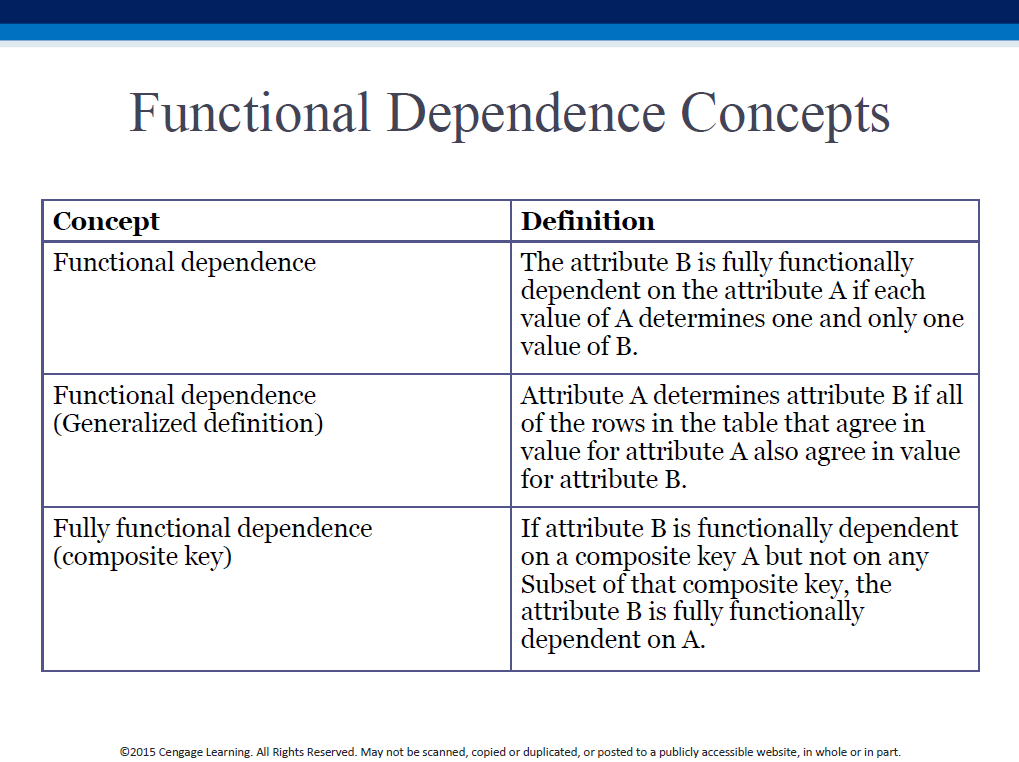

If (A,B) is a primary key, we have partial dependence if (A,B)->(C,D) and B->C [C is only partially dependent on the PK, ie. we only need B to determine C]. In other words, a part of an existing PK is acting like a PK on its own.
If X is a primary key, we have a transitive dependency if X->Y and Y->Z [Z is transitively dependent on X, not directly so]. In other words, a non-PK (regular attr) is acting like a PK.

In other words, "fill in the blanks" so that there are no nulls. Now we have a relation (table), with a value in each cell.
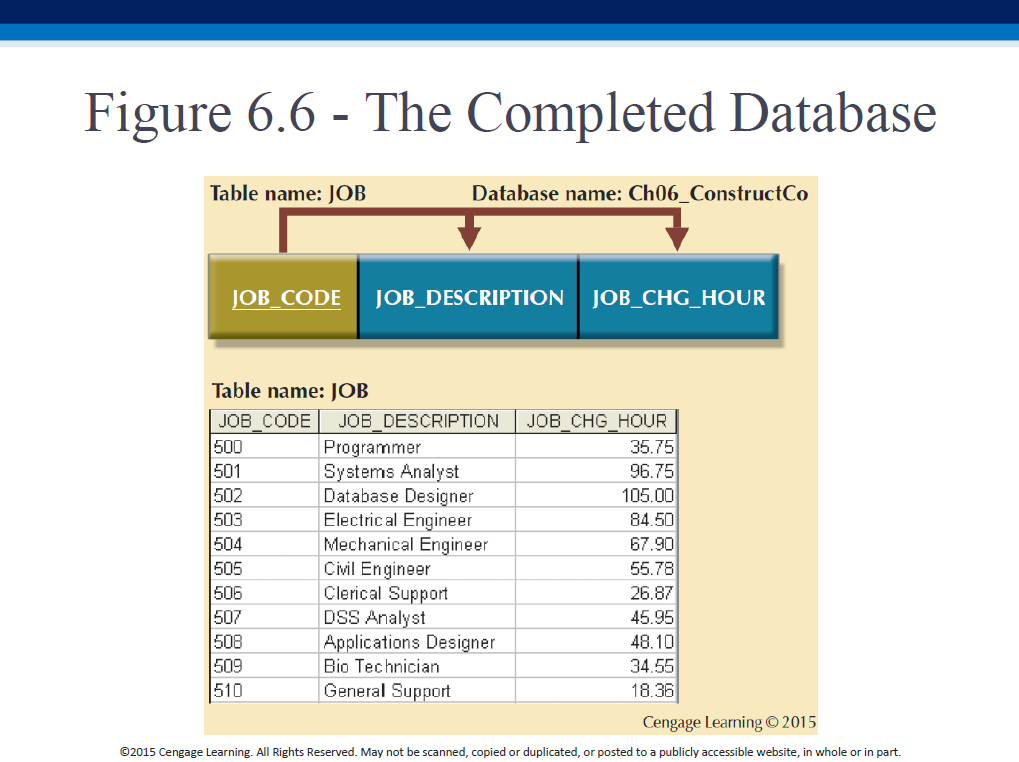
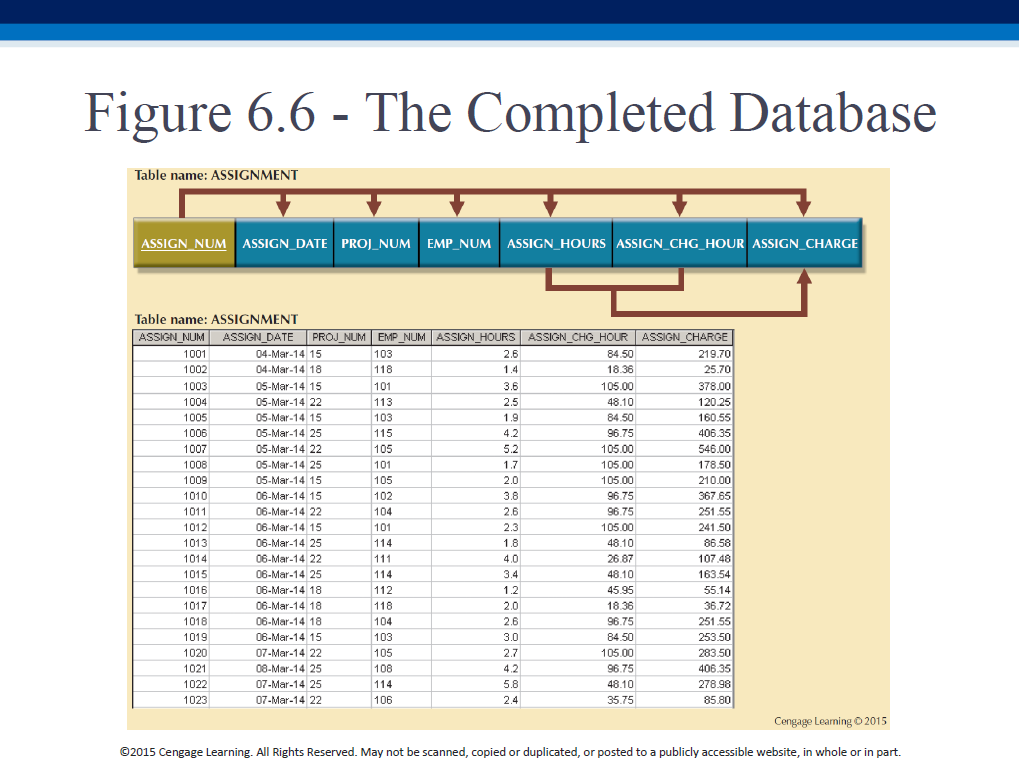
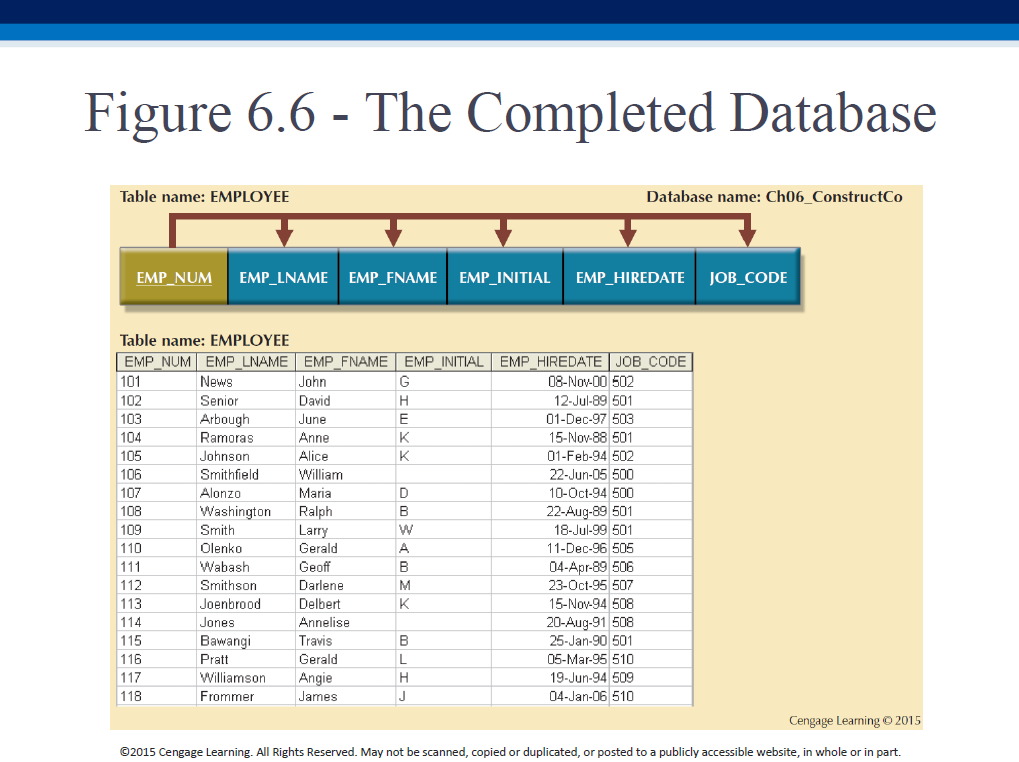
Further, identify the PK! In our example, it is (PROJ_NUM,EMP_NUM).

Create a dependency diagram, showing relationships (dependencies) between the attributes - this will help us systematically normalize the table.
Indicate full dependencies on the top, and partial and transitive dependencies on the bottom. "Top good, bottom bad". Also, color the PK components in a different color (and underline them). Result:
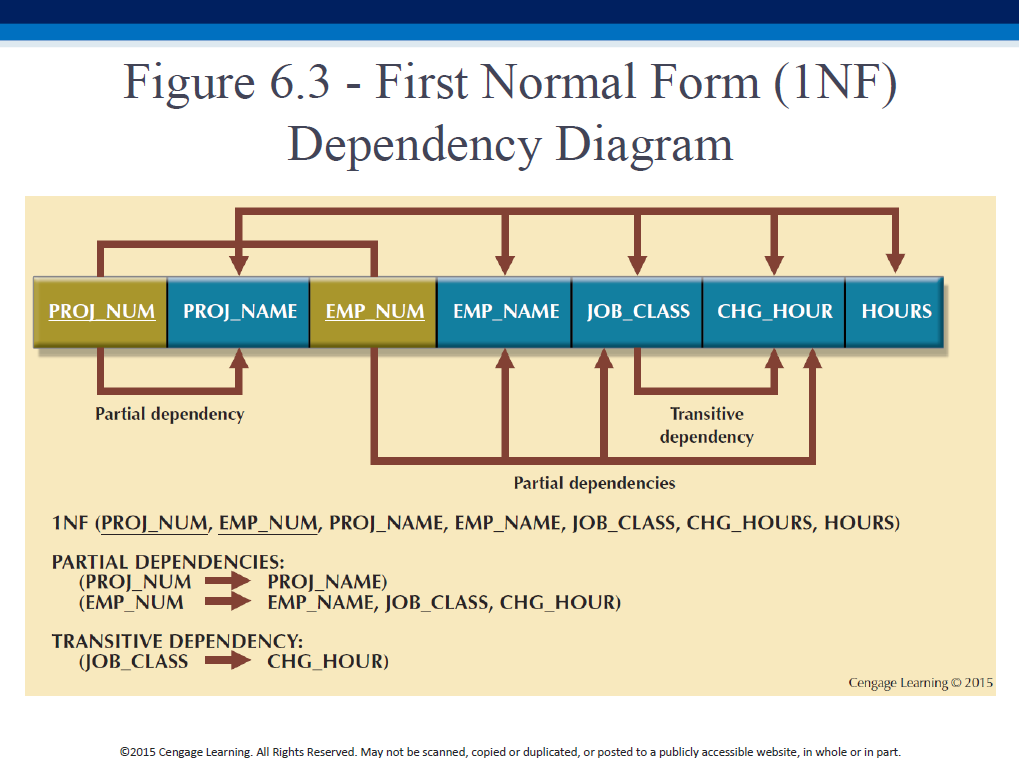
PROJ_NAME has only a partial dependency on the PK (since it is only dependent on PROJ_NUM, which is just a part of the PK).
CHG_HOUR is dependent on JOB_CLASS, which is a non-prime attribute that is itself dependent on EMP_NUM. So JOB_CLASS->CHG_HOUR is a signaling dependency, indicating a EMP_NUM -> CHG_HOUR transitive dependency.


We eliminate partial dependencies by creating separate tables of such dependencies, and removing the dependent attributes from the starter table.

We promote the non-prime keys that masquerade as PKs, into actual PKs (give them their own tables).
Whether we eliminate partial dependencies (to create 2NF) or transitive ones (to create 3NF), we follow the same process: create a new relation for each 'problem' dependency!


We can create a better DB by doing the following augmentations, to the 3NF model we just created:
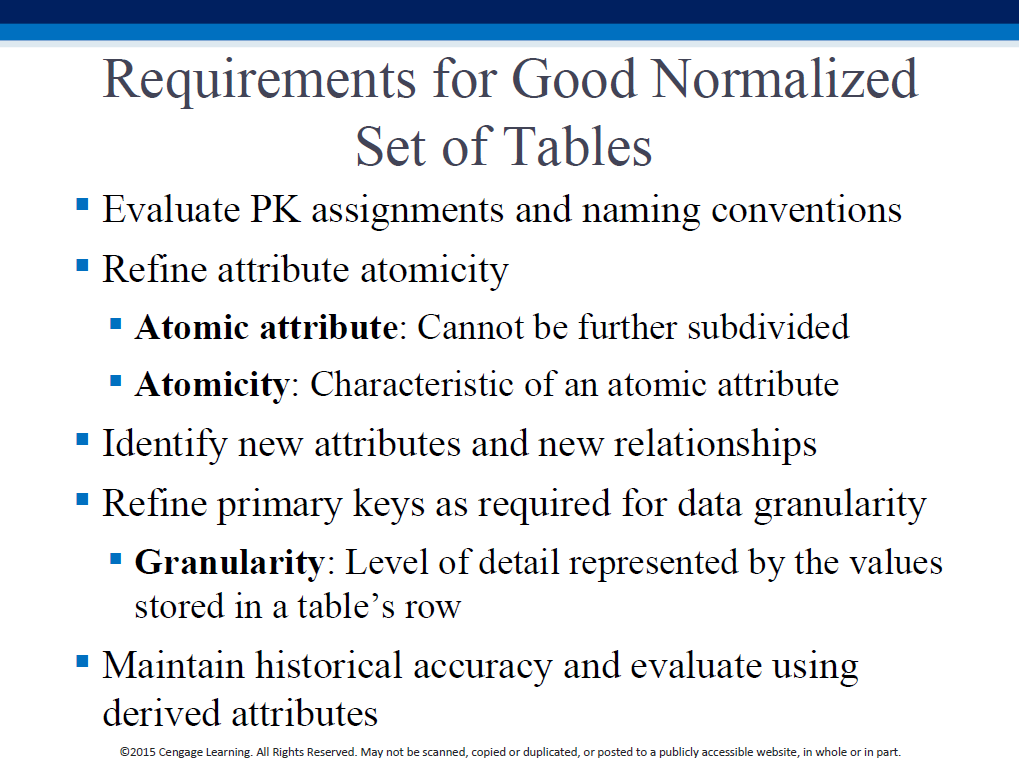
Here is the result of making the "extra" changes to our 3NF form: